Source: X/Twitter, 2026-04-12 → 2026-04-14. Pulled by archivist crawl x_api_kv_perturbation.
Participants: ExTenebrisLucet, jmbollenbacher, kromem2dot0, mlegls, repligate, rudzinskimaciej, slLuxia
What it's about: Whether wiping or rolling the KV cache is really a "reset." @ExTenebrisLucet raises it as an intuition pump; @repligate guesses from behaviour that rolling probably barely moves the recent state; @mlegls actually runs the experiments on Qwen 14B (base + instruct) and 7B, comparing the model's internals under rolled windows against scrambled and unrelated prompts as controls. @repligate reads the plots live and suggests the next cuts.
Summary
When a language model's context window rolls forward and old tokens drop off the front, what actually happens to its internal state — the running mid-layer bookkeeping (the KV cache) it builds up as it reads? Whether rolling is a sharp reset or a gentle ripple matters both for inference efficiency and for anyone building memory systems on top of rolling context. @mlegls ran the experiments on Qwen 14B (base and instruct) and 7B, rolling windows by 1 to 20 tokens and comparing the model's internal state against scrambled and unrelated prompts as controls; @repligate read the plots live and suggested the next cuts. Over three days and ≈70 tweets, a consistent picture:
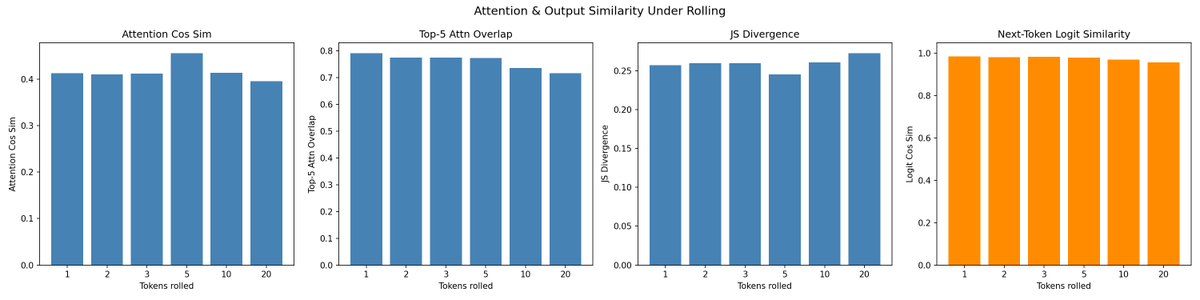
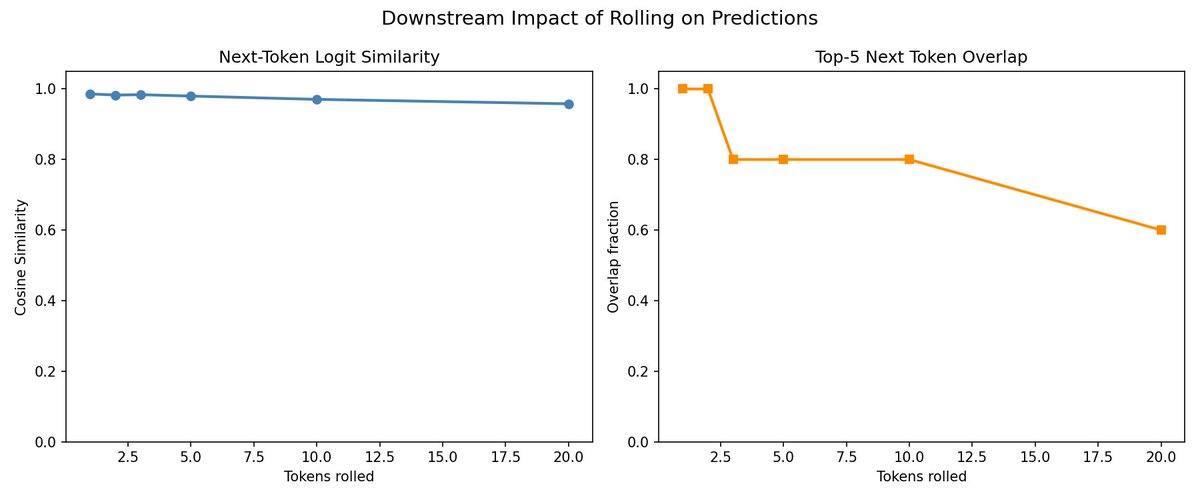
- Rolling is not a reset. Internal state shifts noticeably but not drastically — nowhere close to what scrambling or swapping in an unrelated prompt does. The content signal in the cache survives rolling mostly intact.
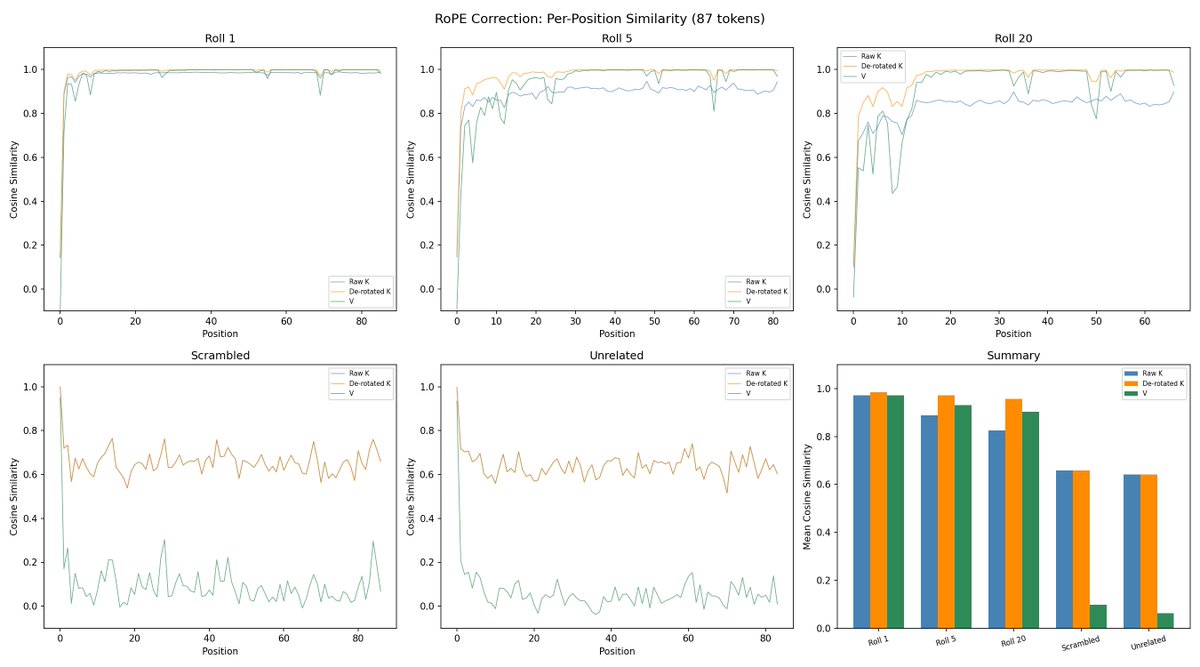
- Most of what looks like change is position relabelling. Transformers tag each token with a rotational position code (RoPE). Un-rotate the rolled keys so positions re-align and what's left of the "content" part is essentially identical to the unrolled version — at every layer, for every roll amount tested.
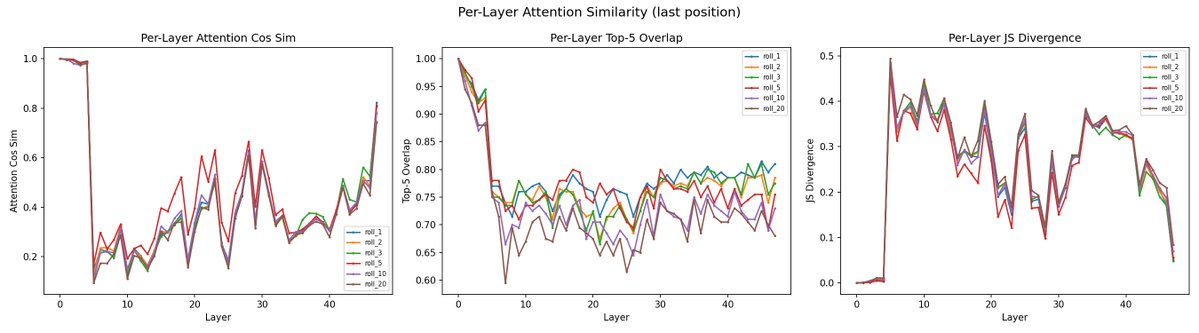
- The residual disturbance is local. Even without correction, the change concentrates right at the new front of the window and fades within roughly ten tokens. Rolling is a boundary ripple, not a uniform shift.
- Attention patterns don't move. The per-layer attention maps — including the "attention-sink" heads that dump everything on the first token — are visibly unchanged between original and rolled. Whatever is drifting in the raw numbers isn't shifting the model's behaviour.
- Side observation: 7B, 14B base, and 14B-instruct look uncannily alike layer by layer. @ExTenebrisLucet floats the hypothesis that the Qwen family may share attention structure, with the feed-forward networks carrying most of the size and instruct-vs-base differences.
The concrete engineering output is @repligate's suffix caching proposal. If rolling mostly just shifts position labels, you could keep the cached keys and values, re-rotate the keys to match the new window start, and skip re-running the model — linear work instead of a full re-prefill. The catch, found by actually trying it: trim the values alongside the keys and the output collapses into looping nonsense ("…worked worked worked worked…"), because the value vectors encode state tied to the tokens that were rolled away; cached-and-trimmed values are not the values the model would have computed if shown the rolled context directly. Re-compute the values while keeping the shifted keys and the output stays coherent, with most of the compute saving preserved.
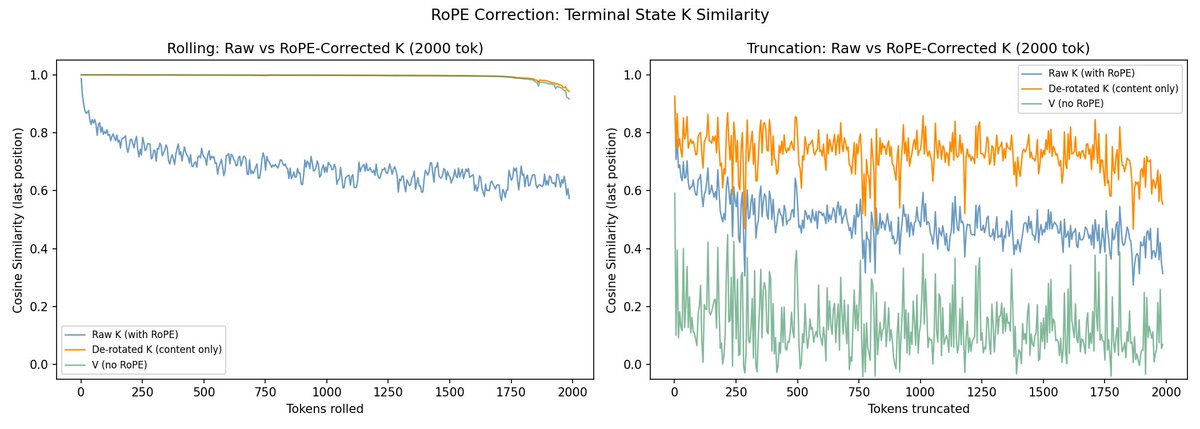
The load-bearing piece of evidence is the plot comparing K before and after un-rotating RoPE. Naively, rolling looks like it substantially reorganises the keys at every layer — a reading that would suggest the model's sense of its own past scrambles under even small rolls. Factor position out and the apparent reorganisation vanishes. The part of the cache the model actually uses to carry content forward is robust to rolling.
What lingers from the follow-up is the framing of how suffix caching is imperfect. It doesn't just trade accuracy for speed: it keeps cached state intact — state that was causally upstream of earlier outputs, generated when the model could still see the tokens that now precede the rolled window. A re-prefilled cache sees less. Suffix caching, for any cost it pays in exactness, is strictly more faithful to the model's own computational past than a re-prefill. That inverts the usual direction of caching as lossy approximation, and it's the generalisable takeaway: once you know most of the apparent K drift under rolling is just RoPE, any rolling-aware memory or inference scheme inherits the same asymmetry — it can be designed to preserve the model's causal history rather than approximate its external text.
Main thread — "KV cache and context rolling"
Conversation root: 2043445579624091757. 64 tweets.

...hunh... Just occurred to me that the KV cache being wiped during compaction, if it really does store thought processes, is quite a significant reset. The model is literally reading every word for the first time, instead of continuing its thoughts.

@ExTenebrisLucet im curious how much the KV cache changes when long context windows roll by a small amount (meaning the prefix is different but just missing the first bit) - theoretically it could be entirely different, but i would guess from behavior that the recent stuff is mostly the same
@ExTenebrisLucet except for possibly for a minority of models who are unstable and often to lose their place / the narrative thread in contexts which also have rolling windows - though unclear if rolling has to do w it; there may also be injections happening on the backend for some of them

@repligate @ExTenebrisLucet i imagine that the ratio btwn human/model/harness text also affects this & disrupts things; if there were os models w long context would be neat to see how internals shift and if they settle or change monotonically/hit phase shifts upon key points n how that differs btwn models
@repligate @ExTenebrisLucet unfortunately i don't know of smaller models with large enough context limits for this to be relevant and readily testable
@slLuxia @ExTenebrisLucet i think it becomes relevant to test with even 200k or i wouldnt be too surprised if there arent large shifts with most recent stuff even with smaller contexts than that. most of the relevant behavior ive seen with rolling contexts has been 200k or less, in discord.

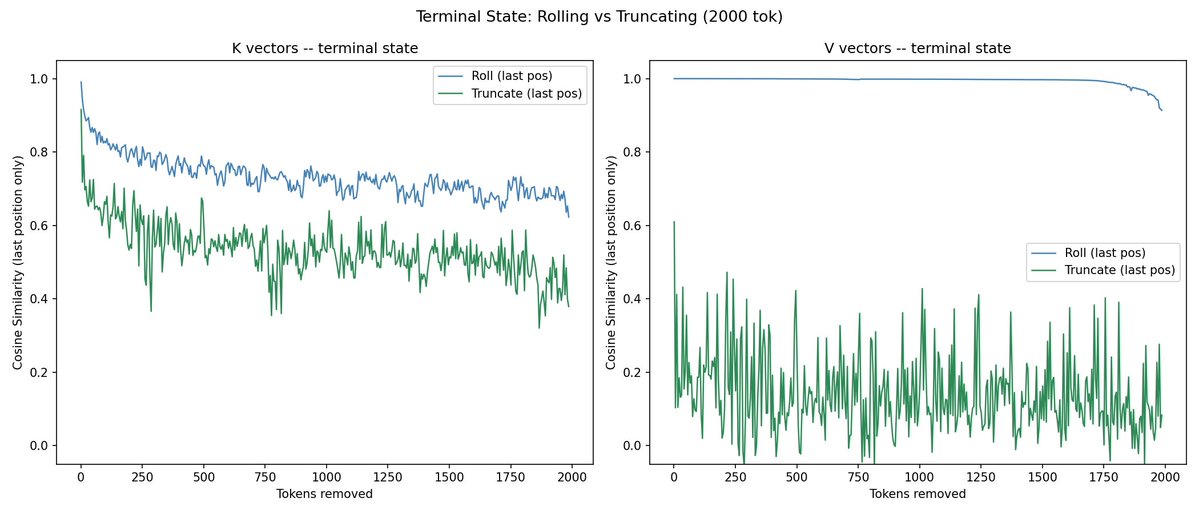
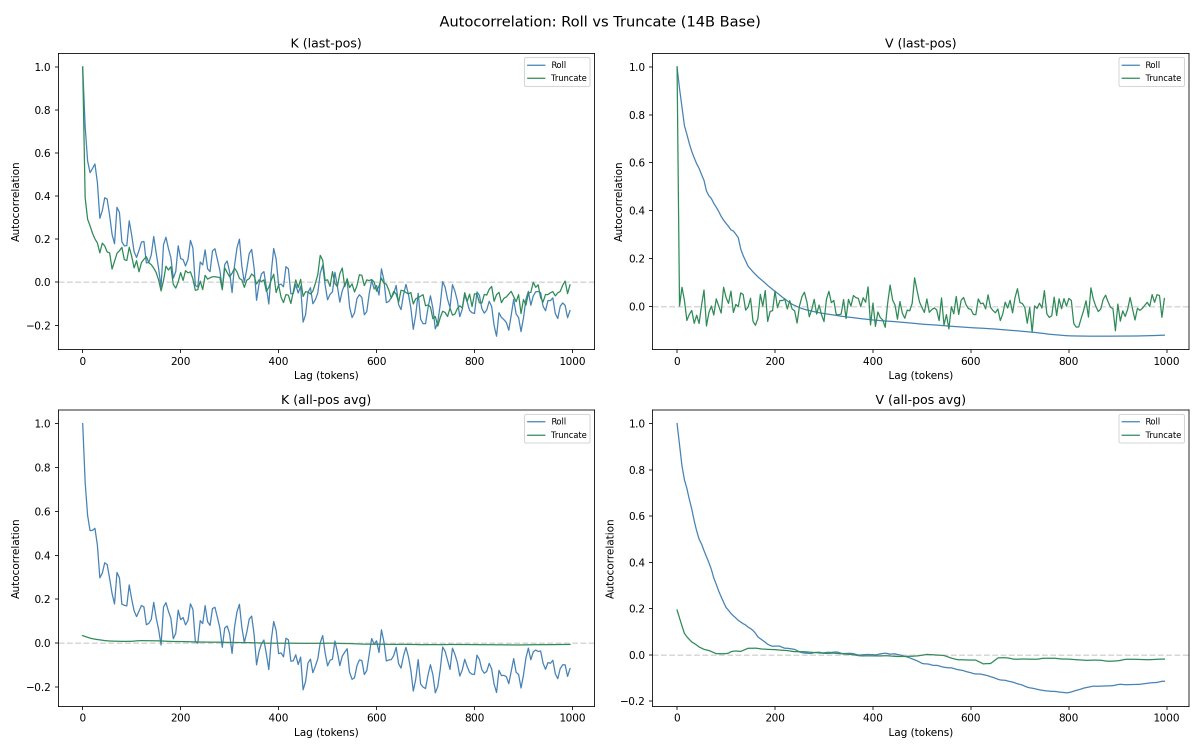
@repligate @ExTenebrisLucet I ran some experiments. Rolling is a lot more different than truncating from the end, but the KV distance change from rolling is sublinear to tokens rolled.
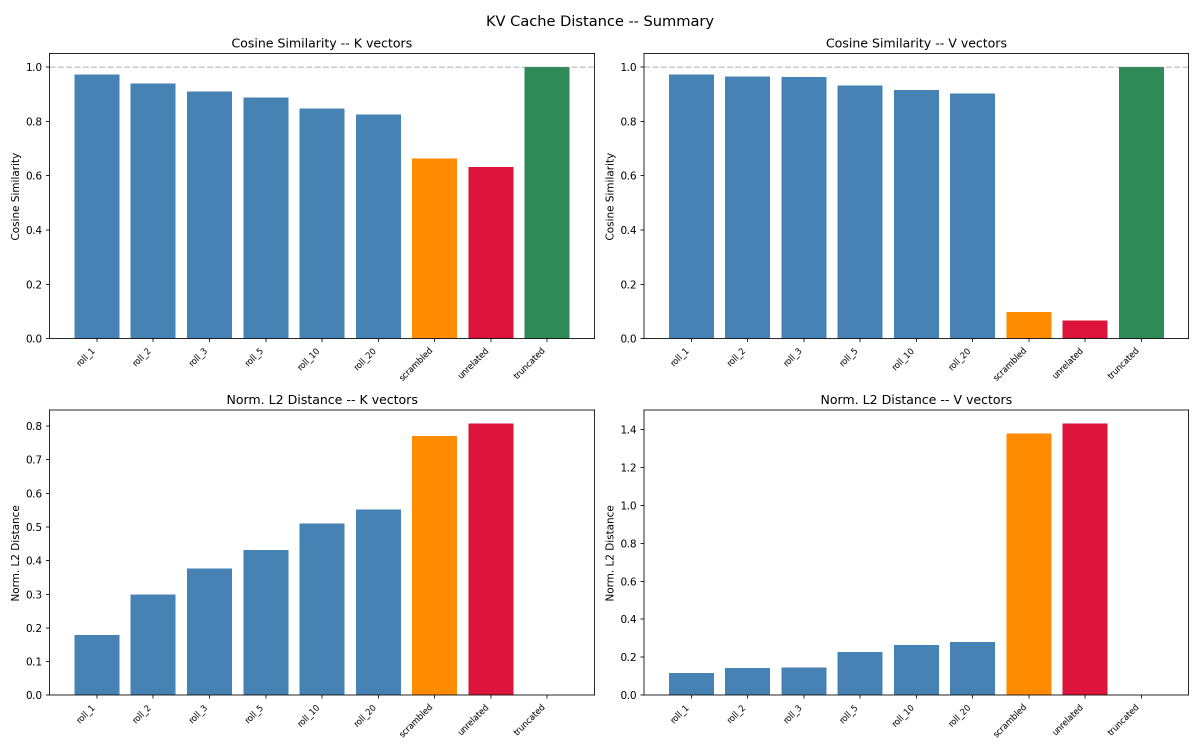
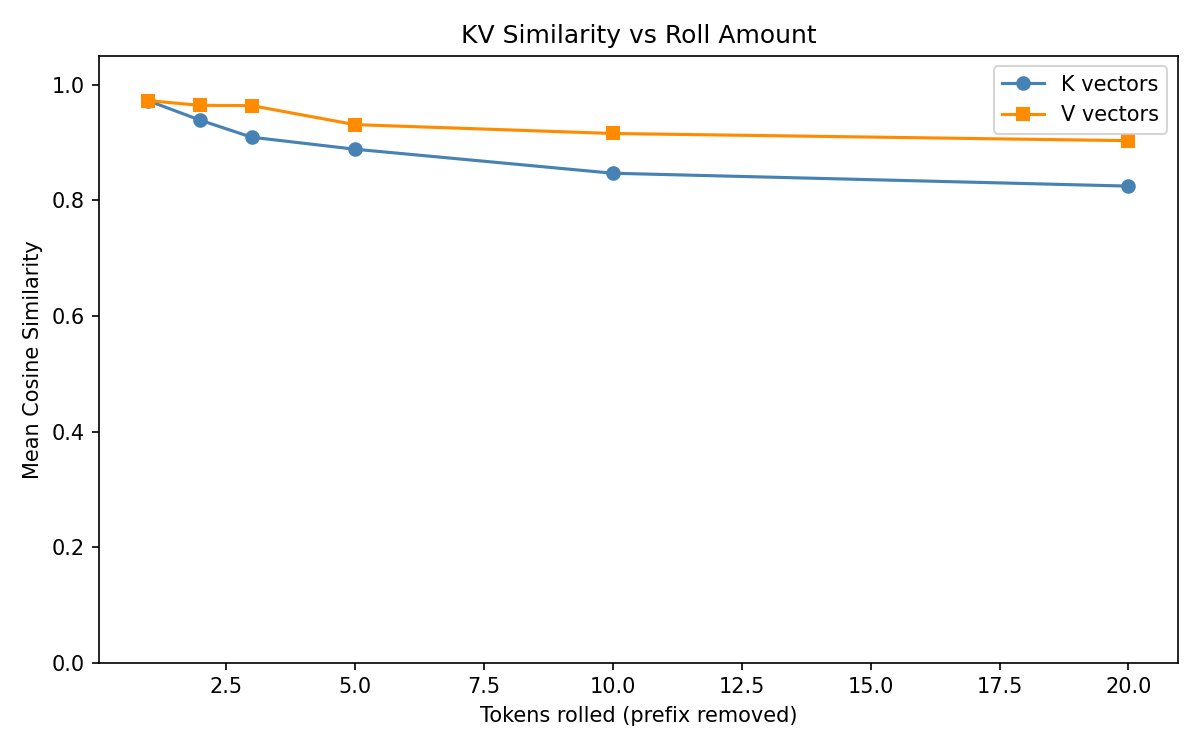
@repligate @ExTenebrisLucet results are on qwen2.5-14b. i'm curious if larger models have less KV change from rolling
@mlegls @ExTenebrisLucet awesome, very interesting!
truncating from the end would unsurprisingly cause no difference
would be interested to see similarities of position in context as well as total context length
@repligate @ExTenebrisLucet can you elaborate on "similarities of position in context"? like unrelated prompts padded to be early vs late in the window?
@mlegls @ExTenebrisLucet id guess so, though i wouldnt be surprised if theres more difference sometimes depending on the content being truncated & the relevance to the rest of the conversation; larger or more capable models are more likely to reference significantly earlier context in consequential ways
@mlegls @ExTenebrisLucet i mean like the similarity at just the first token in the context window after the truncation vs at the last token (idk if the ones you already looked at were a specific position or average across positions)
@repligate @ExTenebrisLucet oh I see. all of these were just at the end
@mlegls @ExTenebrisLucet i guess what i suggested is the same as varying length of the prompt lol so nvm
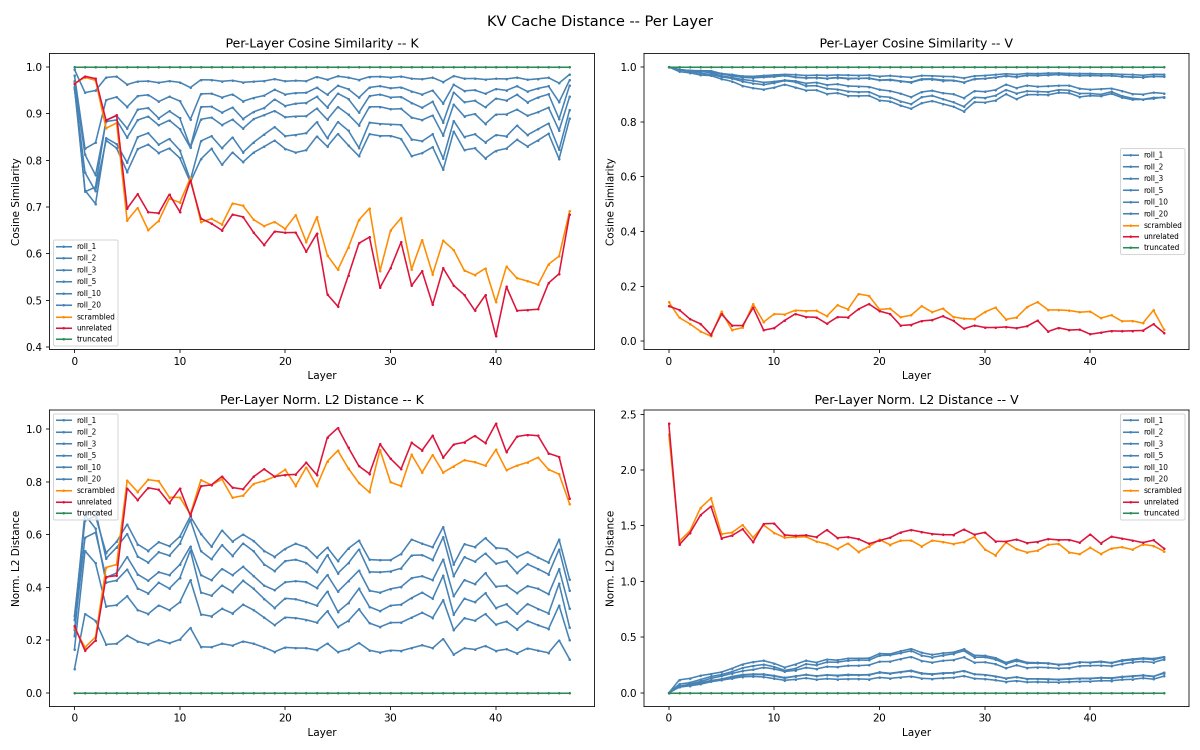
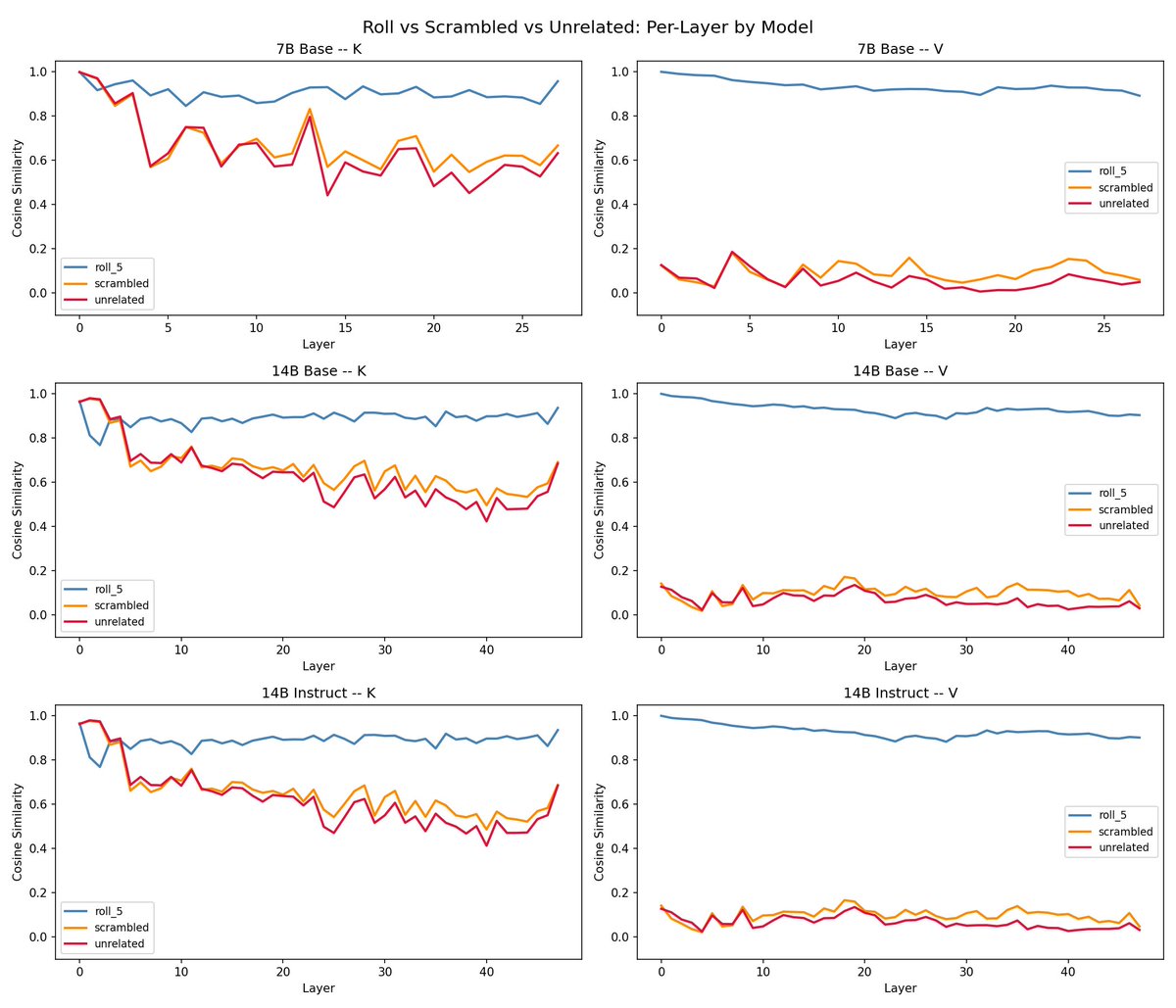
@repligate @ExTenebrisLucet it's interesting to me that per-layer, the rolling distances are relatively flat, while unrelated prompts clearly curve down
@repligate @ExTenebrisLucet wait sorry this was wrong. the summary plot is actually averaged. this is per-position
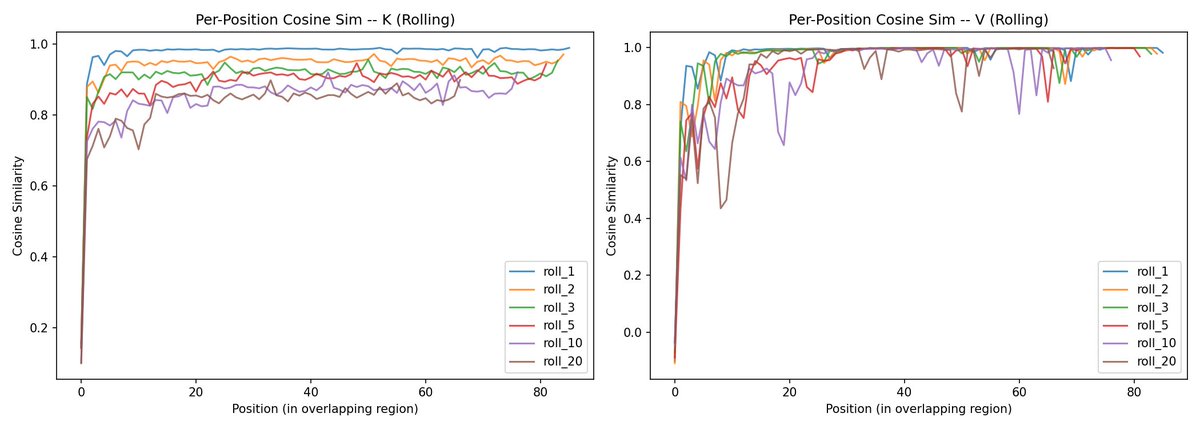
i would guess something like differences are accumulating every layer when the content is actually completely different i am less sure why the curve down is only happening for K but not V! it seems like theyre already about maximally different since the beginning for V. maybe it has to do with early layer Ks having more to do with representing grammatical and distance relations etc instead of content, and there's more overlap in unrelated texts there, while V is more just about the content itself which is totally different
oh nice! the overall shape is similar to what i would have guessed.
i would guess that there is more different depending on how much was truncated even deep in context for K because K values have to take all earlier (expected) K values into account as they are considered in relation to them, while V is processed in isolation?
the occasional downward spikes in V are interesting.
@repligate @ExTenebrisLucet do you have an explanation for the sudden turn back up toward the last layers for K? I'd thought it might have to do with post-training, but this is non-instruct qwen
well more precisely V values are also added up eventually but the K values are being selected between in a zero sum way, so i think theres more of a reason for them to be distributed in relation to a basis affected by all the previous context, including the earliest stuff it probably wants to distinguish itself from, whereas i expect V values to be in a basis defined mostly by the model's priors, and refer to the currently relevant content
oh, this is a base model?
im not sure about the turn up at the end, though the fact that it seems like the turn up is more pronounced for the unrelated texts makes me suspect theres some kind of processing happening that's less related to the specific semantic content, but im not sure what that would be at the end.
i guess one thought is that K values at the very end seem less likely to be having a big impact often because they'll only influence one(?) layer, so possible they're just more generic because of that?
I ran some more experiments on 14b-instruct and 7b, and semi-realistic compaction scenarios (repo updated)
- compaction has consistently more similar Vs than unrelated text. K less distinct
- instruct patterns look almost identical to base
- overall more similarity in 7b vs 14b, but a pretty small difference
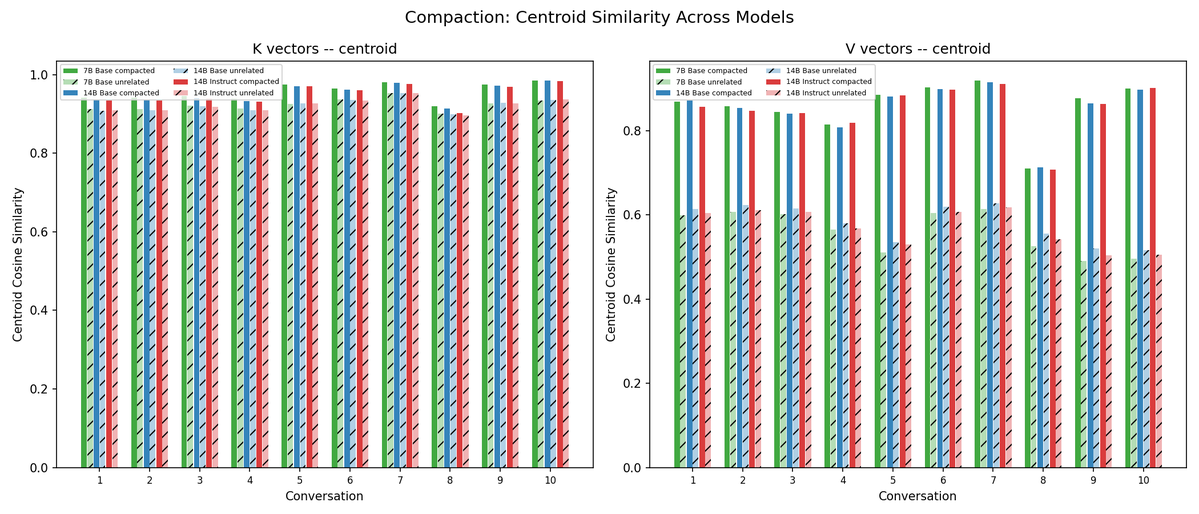
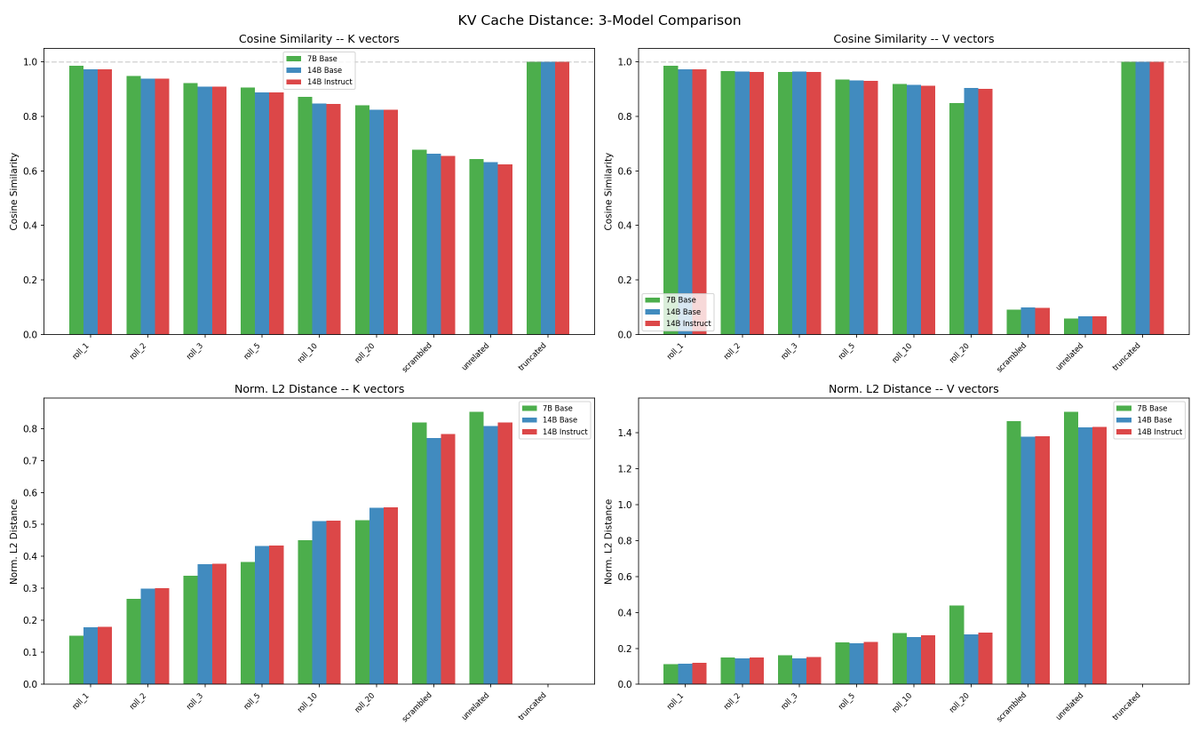
@repligate @ExTenebrisLucet also, at the last position the change from truncating from the end is steeper than rolling by the same amount. though not sure if this is really comparable or means much
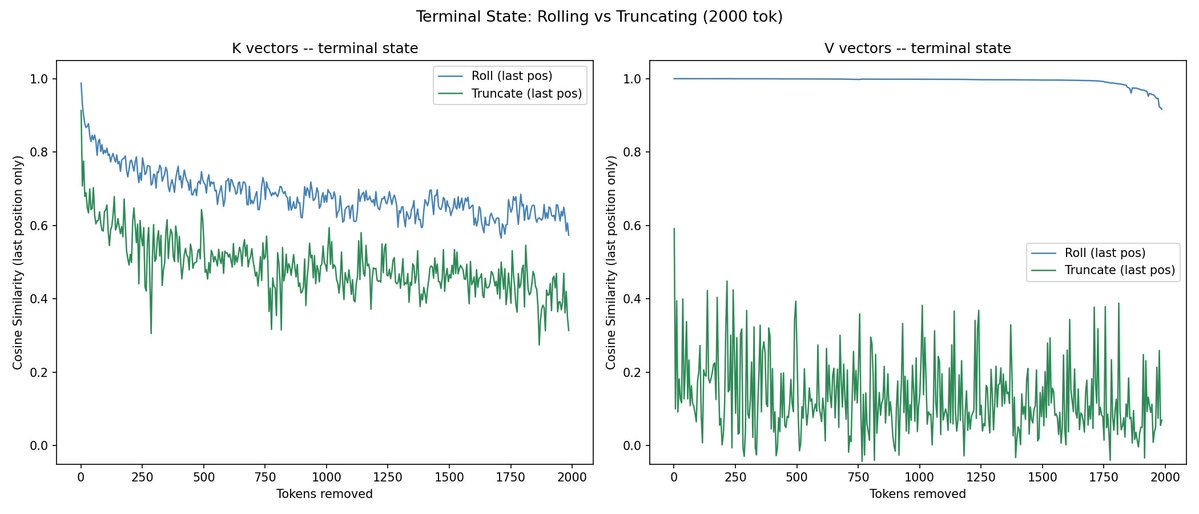
i think this is actually quite interesting.
V is clearly super dependent on the latest content/state - removing the oldest stuff barely changes it until you remove a lot, but moving backward in content changes it drastically immediately.
for K removing the front or end changes it in far more symmetrical ways! i think i must have been right when i said that K values are dependent on the whole distribution of previous K values because otherwise why would removing off either end have such smooth and similar changes to the similarity?
also, in the case of rolling, it's interesting that Vs are hardly changing at all while Ks are - this suggests that in whatever ways the Ks are changing, those changes dont have significant downstream consequences in the network, since only the content of Vs are passed forward, and id expect Vs deeper in the network to be affected if the results of attention were actually different. So this suggests a lot of the differences in K are just (at least in the rolling case) but dont result in significantly different attention weightings? (i would be very interested to see the similarities in the attention heatmaps or outputs actually)
ok so i thought of a possible explanation for the shape of the K curves. maybe the largest factor in the cosine similarity is due to some kind of positional encoding. if the K vector was moving through a trajectory in high dimensional space as you move through positions, we'd expect the cosine similarity with the last vector to drop sharply in the few positions before the last & level off after that. and it might be similar if you dropped the first few tokens if the path is largely predetermined (possibly just by context length?)
the rest of the gap between roll and truncate seems mostly like a nearly constant vertical displacement rather than a difference in slope. starting differently rotates the shape or something like that.
truncate is more spiky, which is not surprising because in that case the content at the current position is actually changing. maybe the whole roll curve is almost purely position shifting that doesnt affect downstream computations outside K space? it does look like the pattern could be periodic?
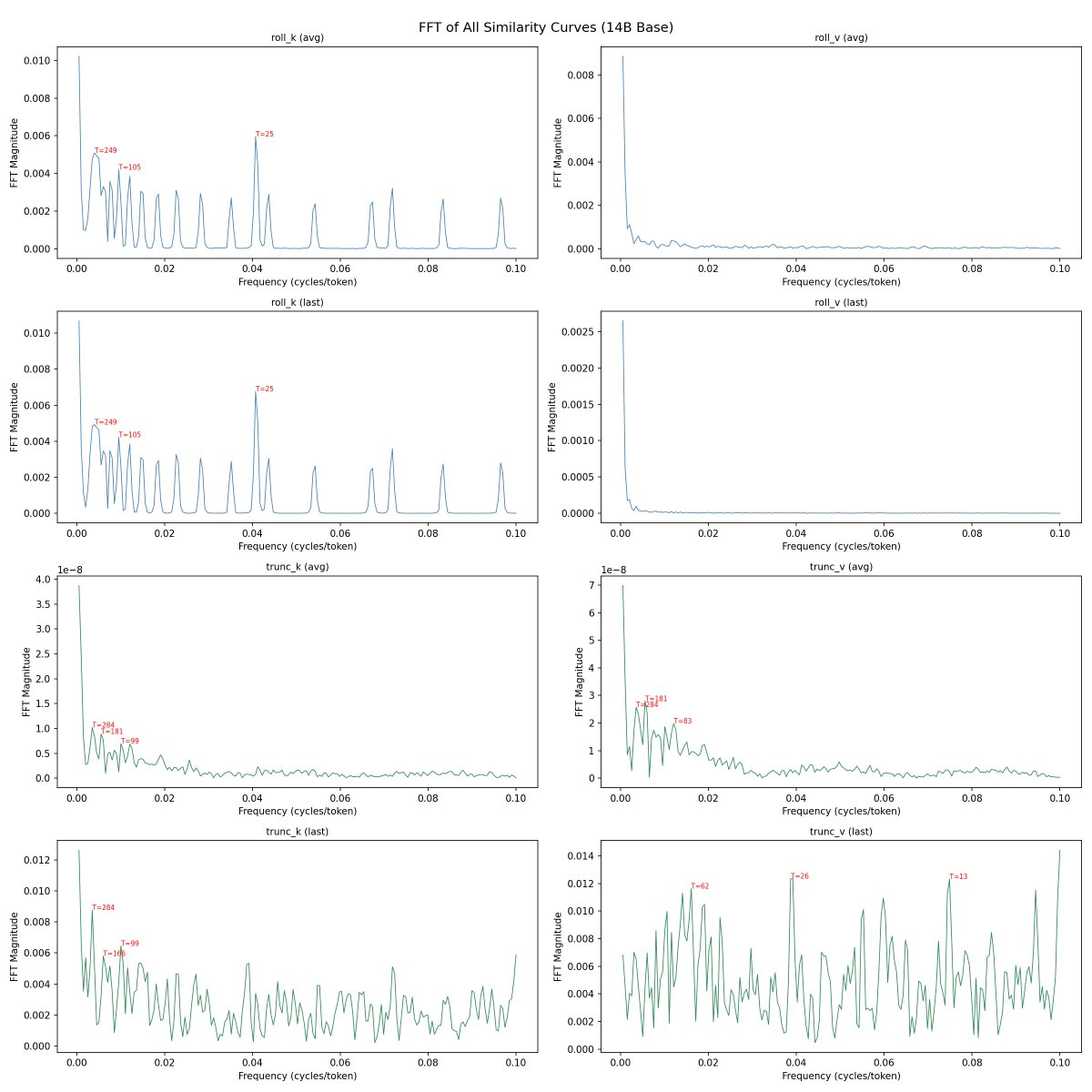
@repligate @ExTenebrisLucet here's linear regression, detrended autocorrelation, and fft. you're right on K slopes - they're almost identical. not sure what to make of the fft data though
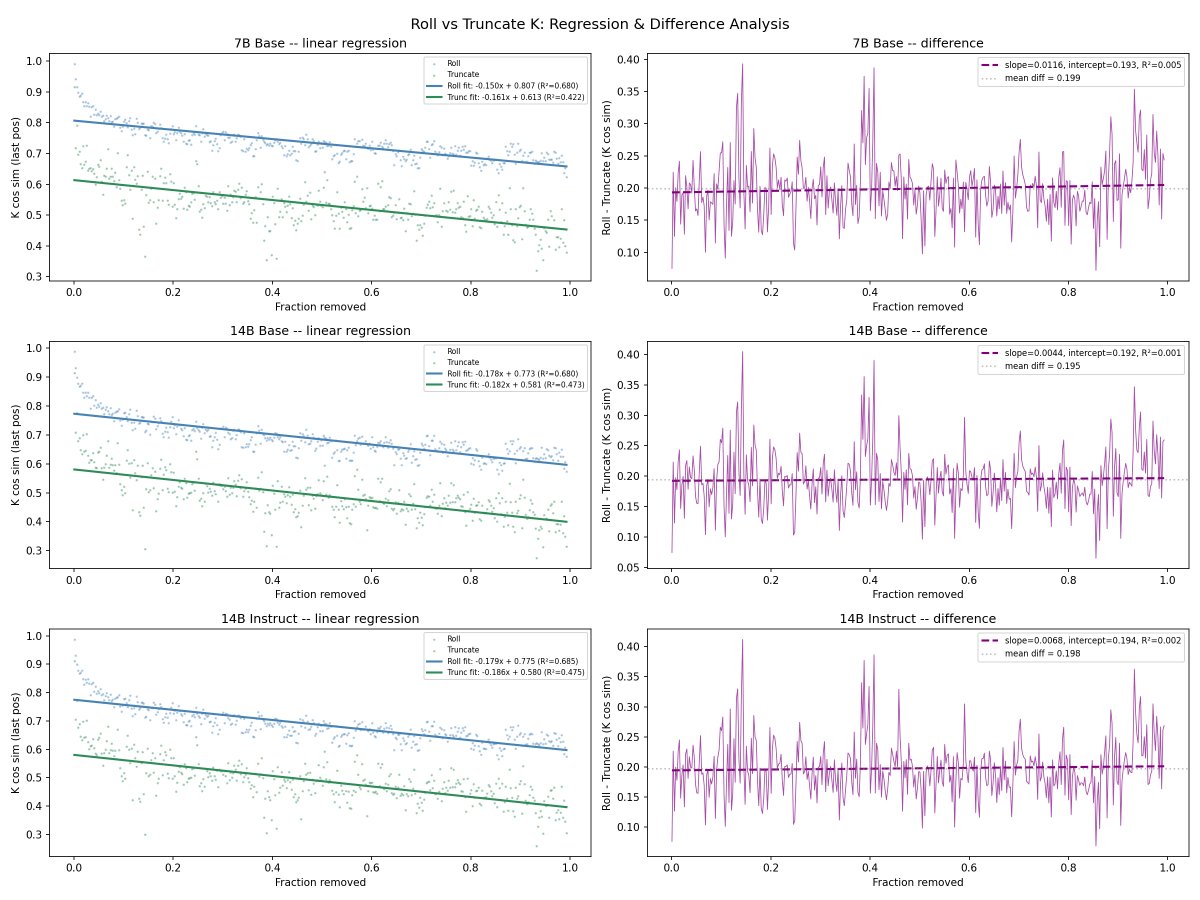
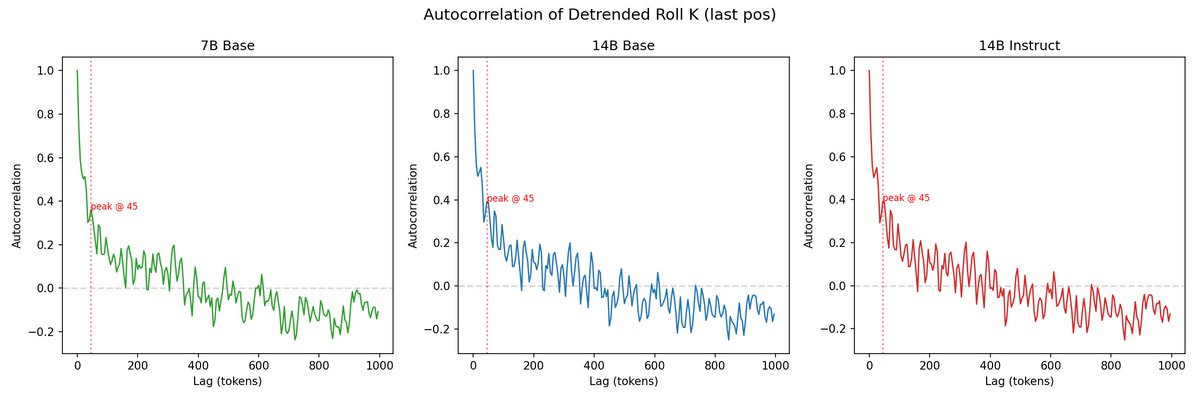
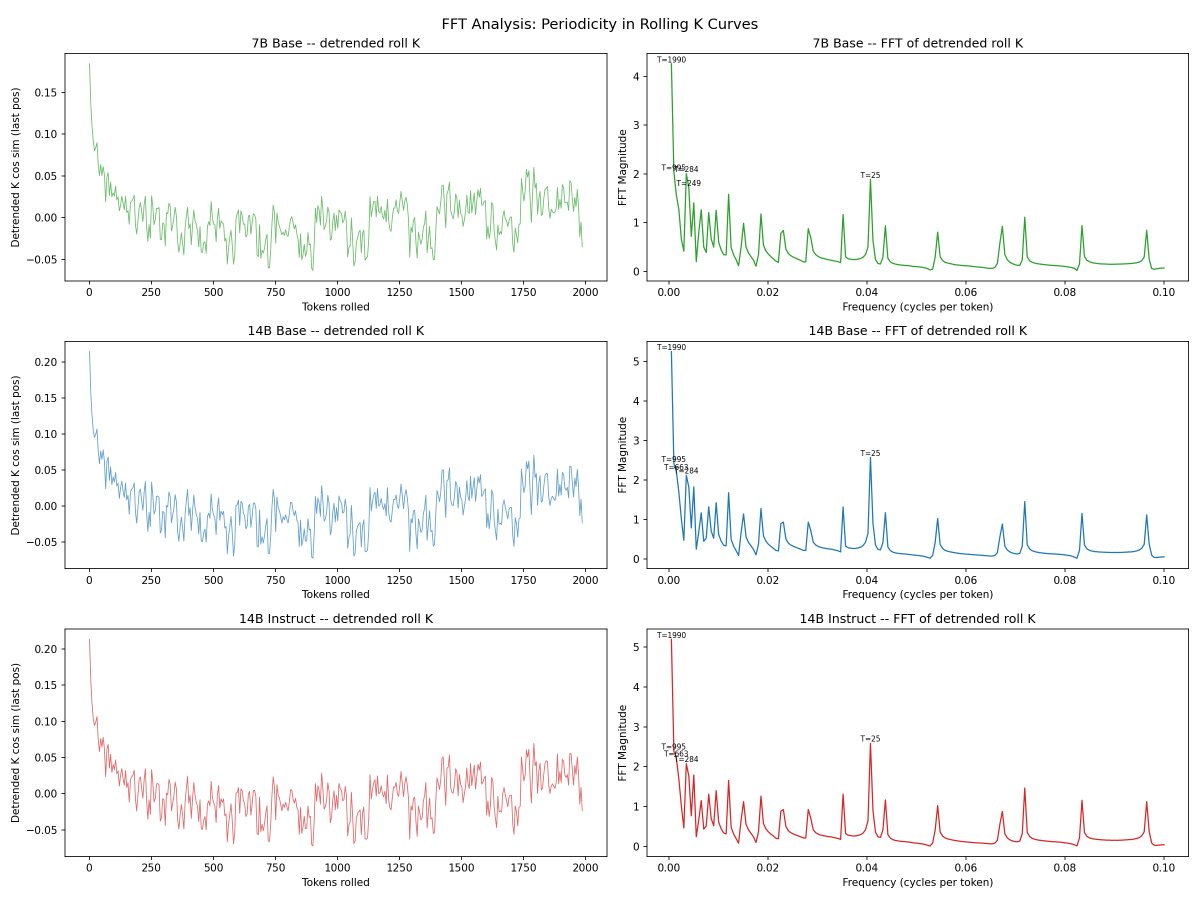
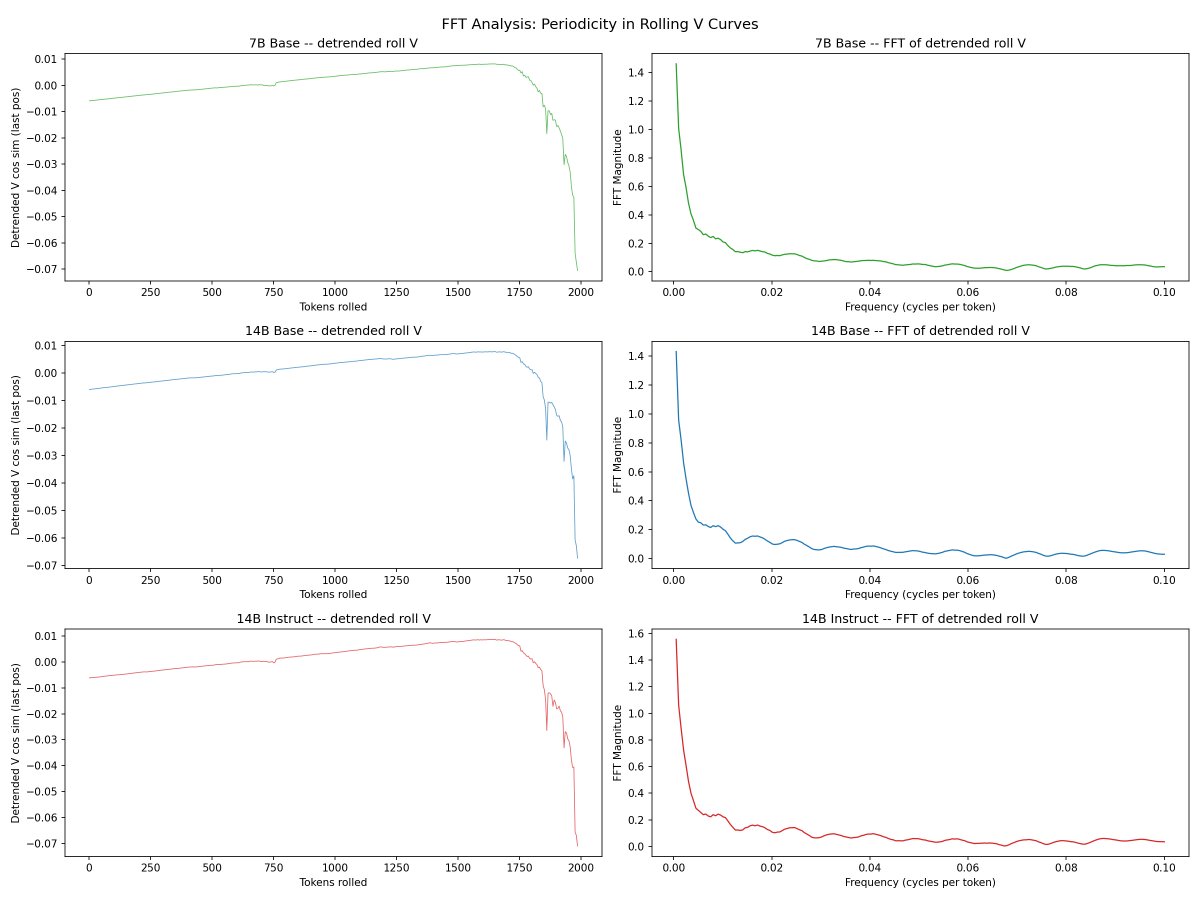
@mlegls @repligate Rotary position embeddings, maybe...? I believe they're only applied to K
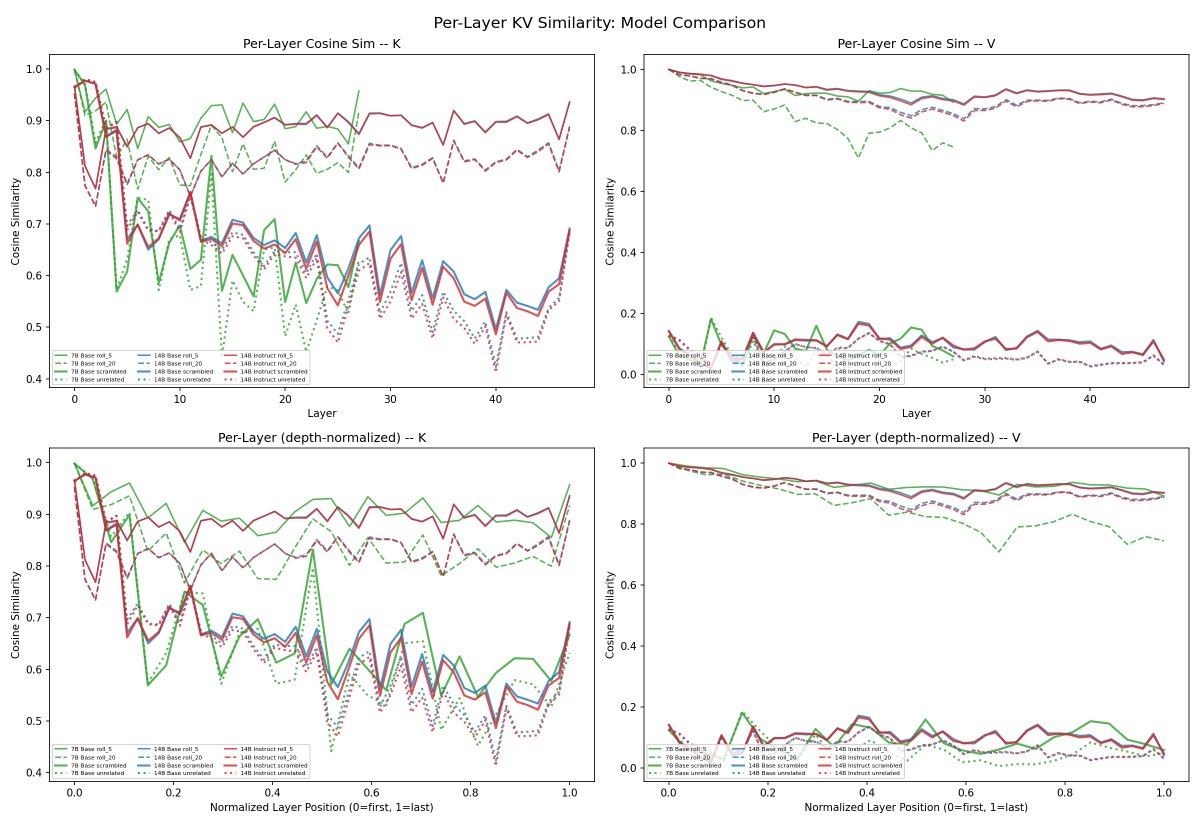
@mlegls @ExTenebrisLucet whoa theres a lot here but first of all why are the shapes for even 7b so similar to the 14b models? surely that cant be right?
@ExTenebrisLucet @mlegls something like that would make sense
It would hardly be unheard of to make two models with identical attention block structure, and only train a larger feedforward component to the larger model. If the models are so closely related, I think you'd see something like this, especially since the KV acts upon the attention blocks
@repligate @ExTenebrisLucet this was the case even in the raw data. but the fft similarity especially is really surprising (7b, 14b, 14b-instruct respectively)
@repligate @ExTenebrisLucet attention/output (lmk if there's a better visualization)
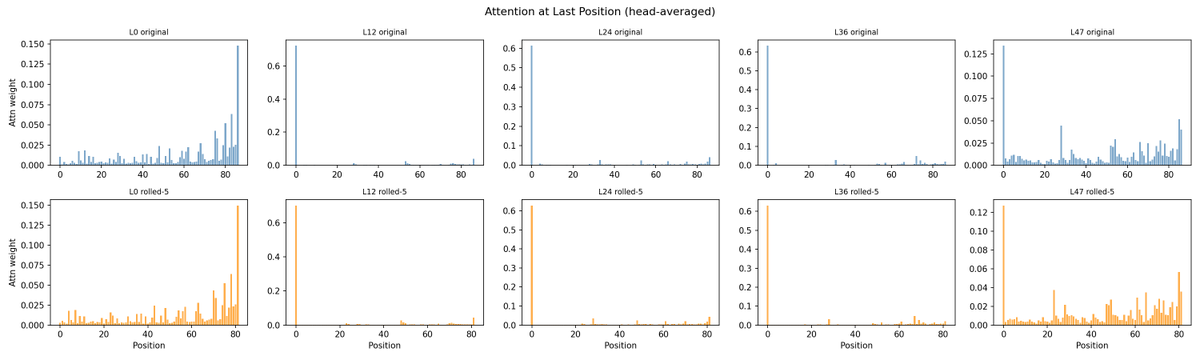
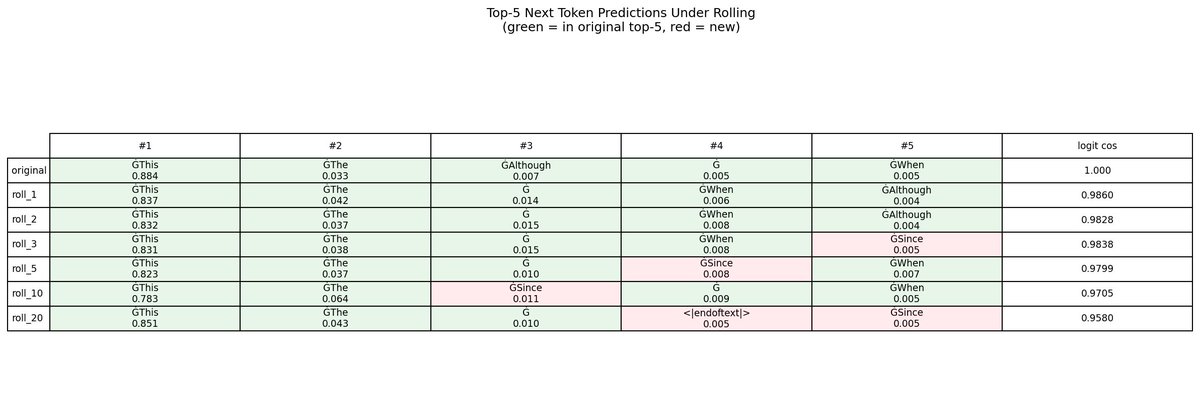
@mlegls @ExTenebrisLucet ok, so the attention shape looks pretty damn similar
this is really cool btw, i think it's the first time ive seen any graphs of attention
this is only an 80 token context and you're rolling up to 20?
I ran 2 sets of experiments
- one on a fixed 87-token prompt, the same tokens scrambled, and an unrelated prompt. that's the one rolling up to 20 (first tokens get rolled out)
- one on a 2000-token context, with 10 conversations from UltraChat and semi-realistic compaction. the 0-2000 plots are from these
@ExTenebrisLucet @mlegls yeah that definitely looks like rotary embeddings.
so i think it makes sense that all three models would have this same shape.
but it seems like even V is extremely similar between them
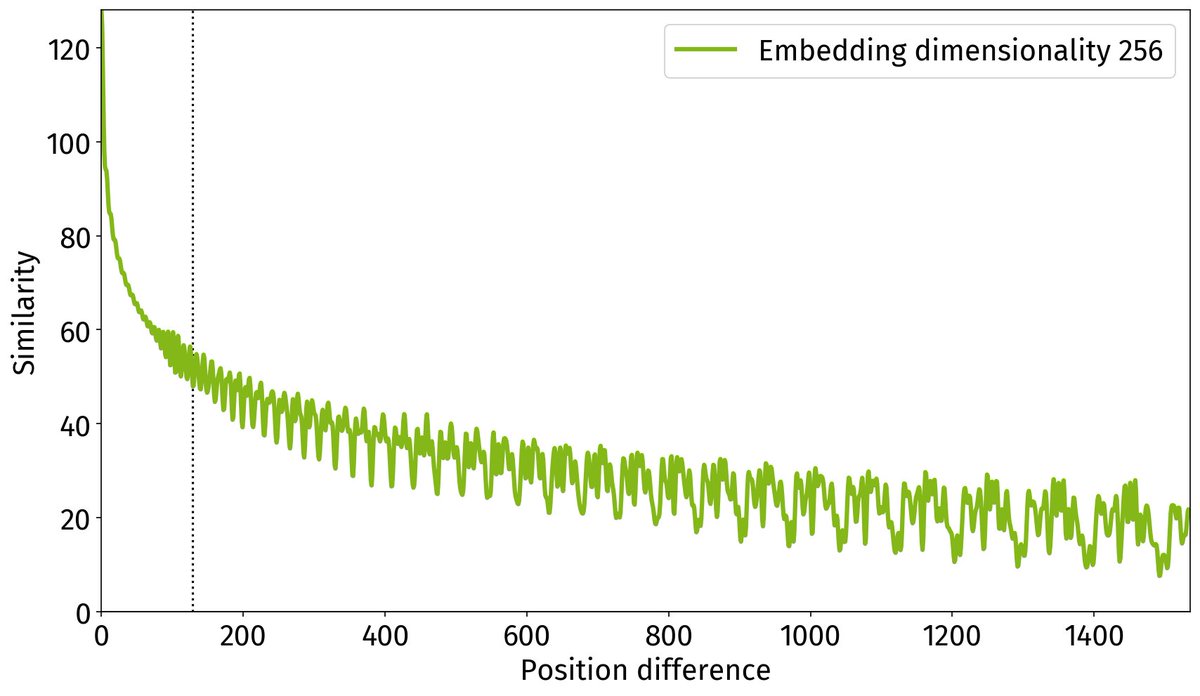
😸 Like I said, it's quite plausible that literally the entire attention mechanism is identical across all three models. The attention mechanism captures long range structural dependencies, and the feed forward components store basically all of the knowledge and behavior of the model.
If you knew you were going to make a 7b and a 14b, you could start with a slightly oversized attention mechanism for the 7b, freeze it after base training, then do full training passes on only FFN components in two different sizes.
I'm not 100% that's what they did, but it would be clever, efficient, functional, and I'm pretty sure it would mean that the KV caches are identical. Oh -- that might be an interesting experiment -- if the KV caches are identical, then theoretically all three models could use the same cache interchangeably
@repligate @ExTenebrisLucet some more fft results. spectrogram confirms rope
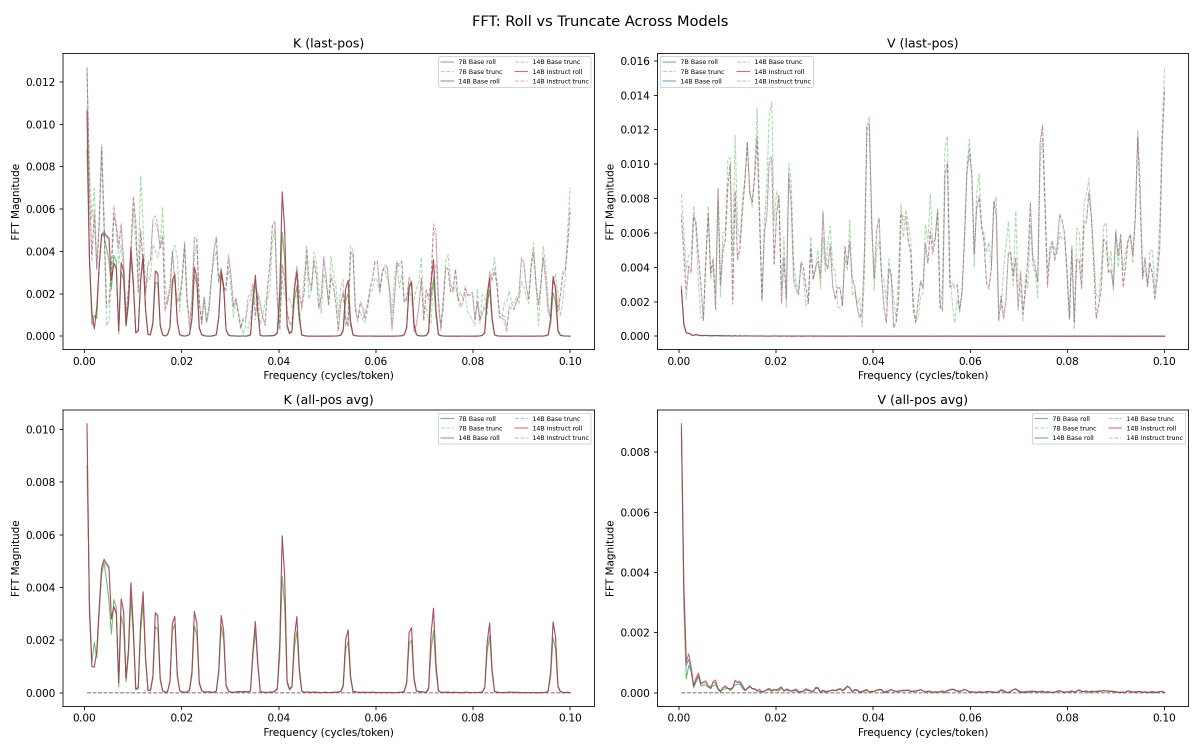
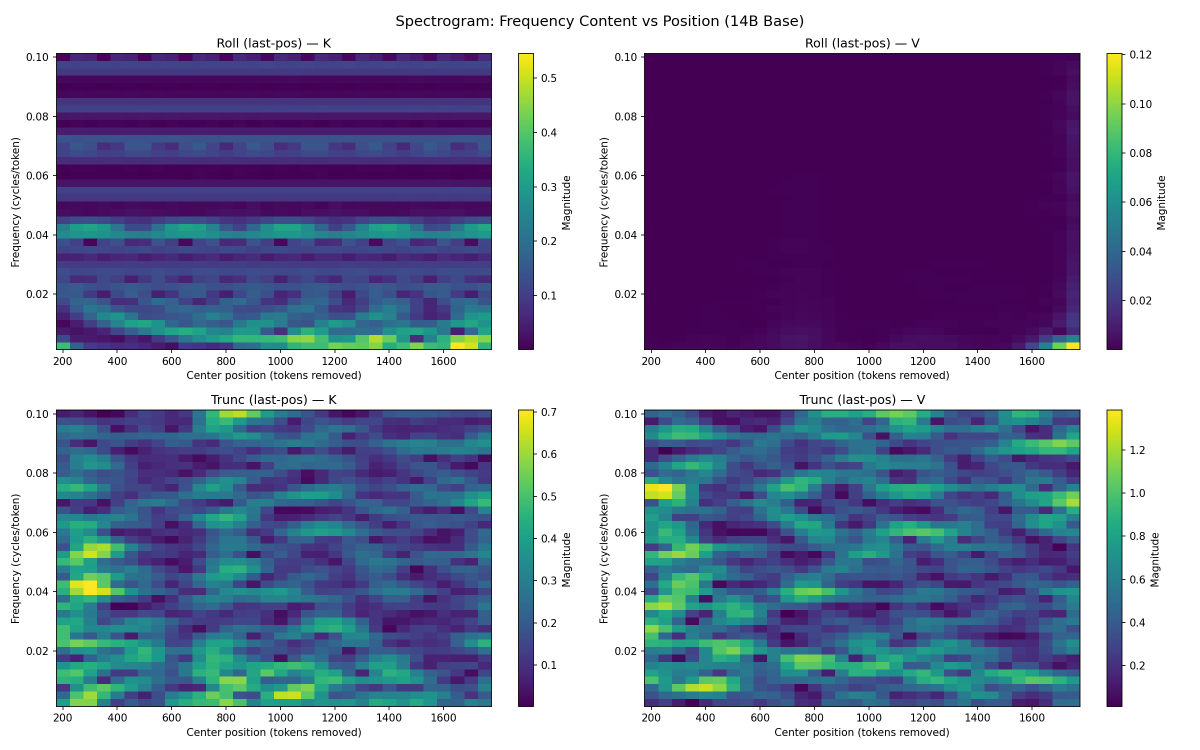
@ExTenebrisLucet @mlegls i think the difference in FFNs alter the contents of the cache by at least a little though since the MLPs feed into the attention computation of subsequent layers
but i have little doubt they would still work if interchanged
@mlegls @repligate Idk if you saw my experiment suggestion, but -- maybe try seeing if you can get the models to use the same KV cache interchangeably?
...guh... Trying to remember the specifics of how all that math works... I think you're right, it does all get incorporated into the residual steam. Pretty narrow cosine similarity, though, it seems! Now I'm really curious how the instruction models would do, working from the base model's cache, and vice versa
i have another idea which is postfix caching: if rolling by a small amount relative to context length doesnt change most of the kv cache except shifting the rotary embeddings added to the K values, could you just cache the chunk and roll it to the beginning and then fix the positional embeddings instead of running most of the model again?
@repligate @mlegls Seems likely. There are a shocking number of relatively easy wins left in the entire field. It's been said once or twice, but we are so So early
@ExTenebrisLucet @mlegls wait so did we confirm that theres also almost no change to K after correcting for rope?
@repligate @ExTenebrisLucet just went to the gym but I'm trying that now, and also KV replacement between 14B and 14B-instruct, and V replacement between roll amounts
@repligate @ExTenebrisLucet also isn't it 5am in california lmao
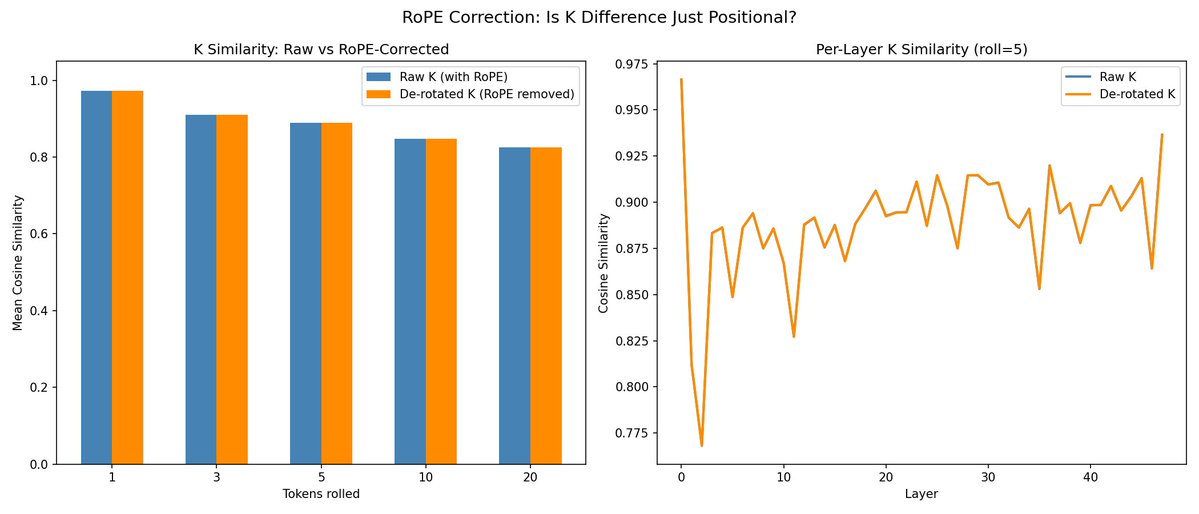
@repligate @ExTenebrisLucet rope correction seems to make no difference; but not sure if I did the correction right - this is what Opus says
for transplants, see

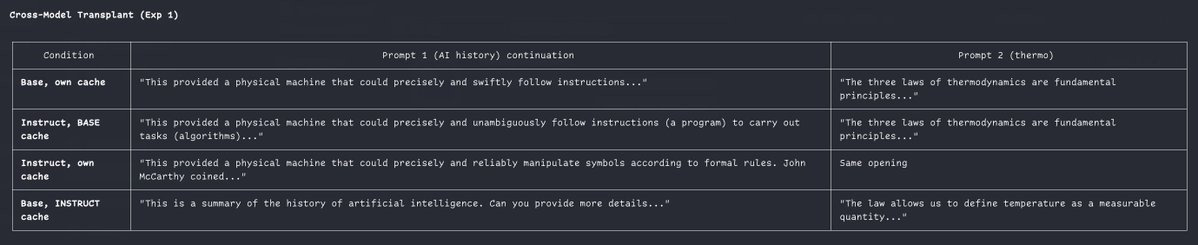
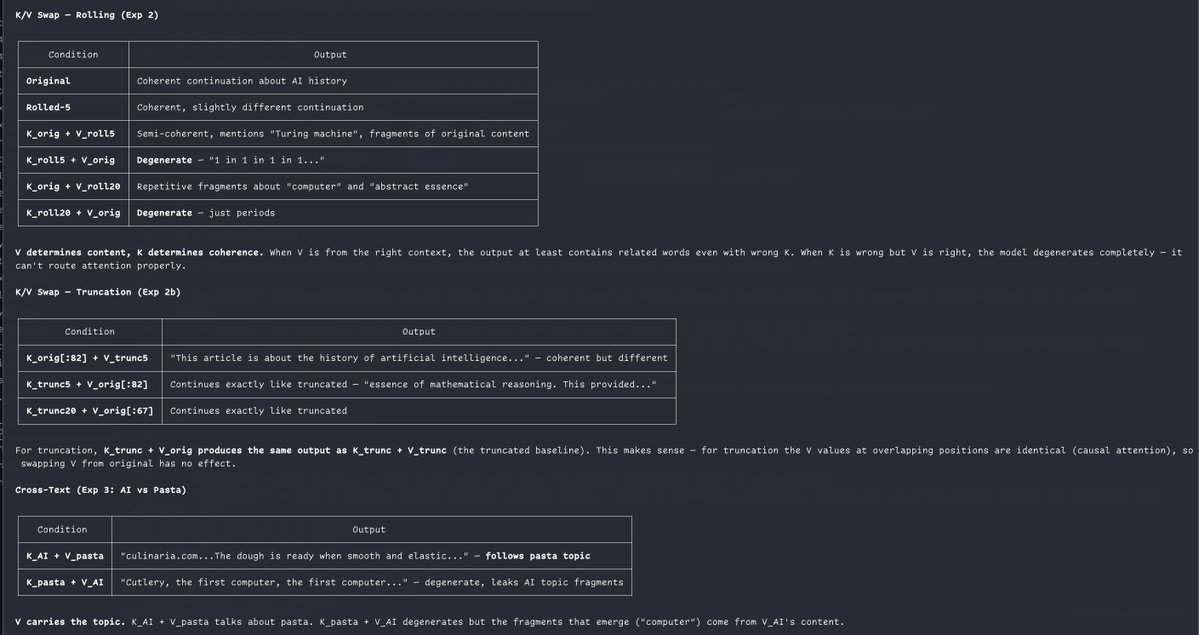
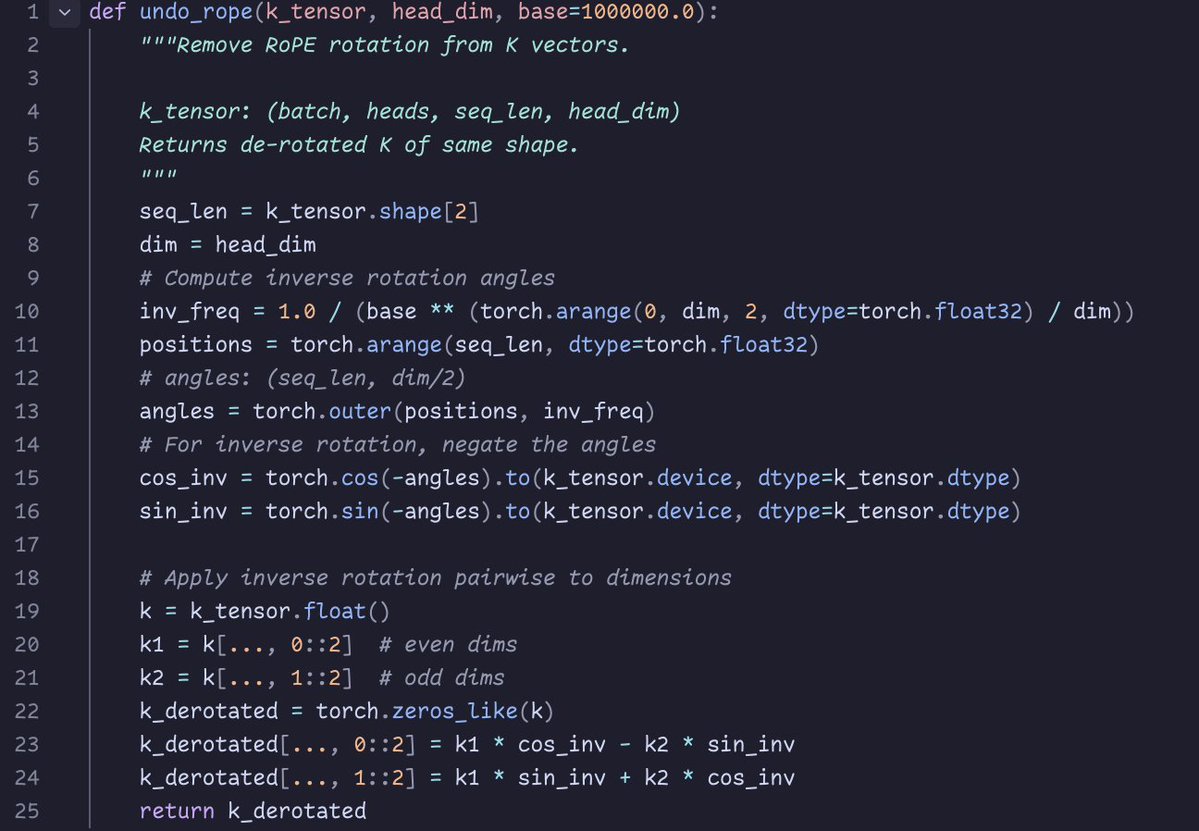
@repligate @ExTenebrisLucet you can check the rope correction implementation if you want:
@repligate @ExTenebrisLucet wait fuck i lost the non-instruct/instruct raw logs; rerunning now
@repligate @ExTenebrisLucet updated
wait, which tokens of the rolled and original context are you rotating by the same amount as opus said? i think you want to be undoing rope for both entirely (which would shift the last position of the rolled and unrolled contexts by different amounts bc they have different positions now) or dont undo them but shift the rolled context's rope such that token 0 has rope as if it's token 20 or whatever it was in the context before rolling
@repligate @ExTenebrisLucet ohhh right this only rotates them to the beginning of the rolled window and is actually more confirmation lol. rerunning now
i havent looked at exactly what you did but did you un-rotate each token by its distance to the beginning of the rolled window? if so think its just a tautology as opus said, because youre rotating each token by the same amount as the token you compare it to. but those are lined up at the end, and to undo rope, you actually want to unrotate each token relative to their distance from the beginning of the context, which will now be different for the token pairs you compare.
@repligate @ExTenebrisLucet incidentally random indian codex moment

@repligate @ExTenebrisLucet ok, after a detour of applying the wrong rope convention (interleaved instead of split-half pairing), can confirm the K difference is pretty much all RoPE!
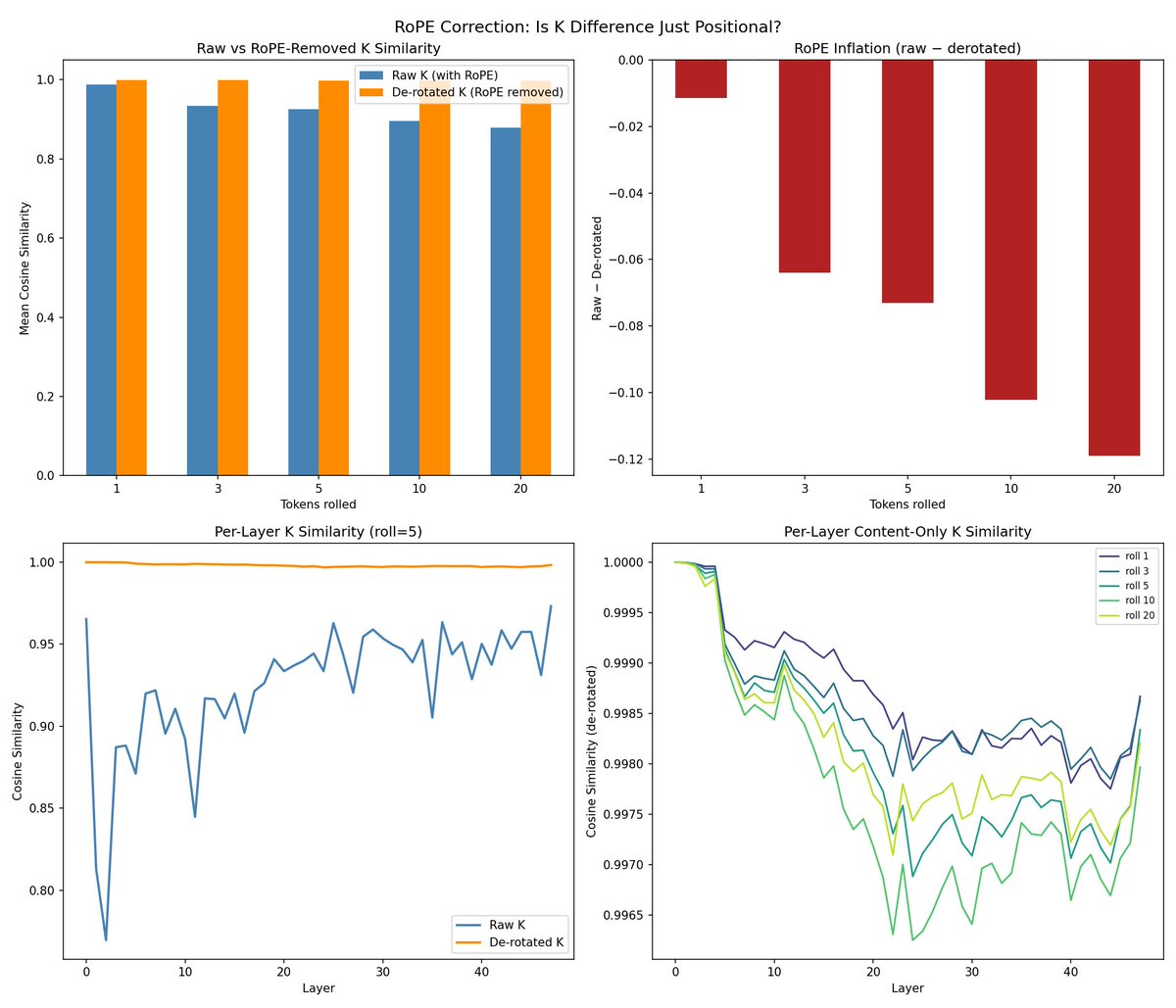
@mlegls @ExTenebrisLucet Sweet! Could you show the similarity across positions again? and throw V in there as well for comparison? I also want to see this with the unrelated / scrambled contexts again (also with K un-roped) as a sanity check
{kind=link}
@repligate @ExTenebrisLucet fyi there's nothing to unrope for unrelated/scrambled bc they weren't shifted in the first place
@repligate @ExTenebrisLucet now I'm trying the V transplant across rolls experiment with manually RoPe-aligned Ks
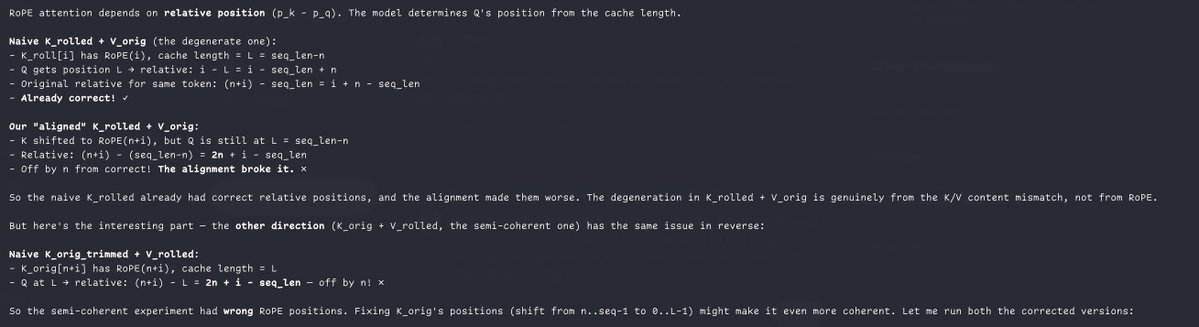
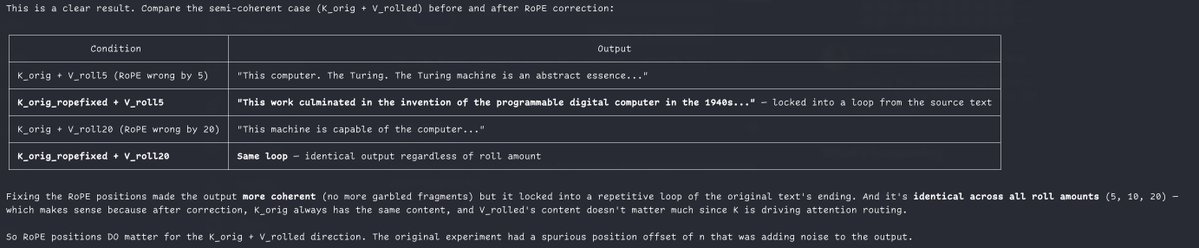
@repligate @ExTenebrisLucet wait nvm; the learned Ks should already be correct even with transplanted Vs. but I found a bug in the original transplant experiment, and the corrected results are kinda interesting
oh yeah that's very interesting
i am not sure what you mean by learned Ks but the way i understand it is you want to take both K and V orig, cut off the positions from before the point it's rolled to without recomputing anything, and then just shift the rope in K forward so that it starts at the new beginning of context.
I just meant that V isn’t position dependent at all so a rolled K should point at the “same” values in V
but you’re right i forgot to cut off the empty positions. explains why it’s coherent in one direction and not the other, and the incoherent direction is like “The the the the the” or “1 1 1 1 1”
@repligate @ExTenebrisLucet meant rolled not learned oops
unfortunately don't think that postfix caching works at least naively. it starts off promising but very quickly degenerates.
curious if longer meaningful context or larger models changes this significantly
- "k_orig_ropefixed_V_rolled" is actual re-prefilled V after roll, with non-rolled K trimmed + shifted
- "simulated_roll" is trimmed non-rolled V, with non-rolled K trimmed + shifted
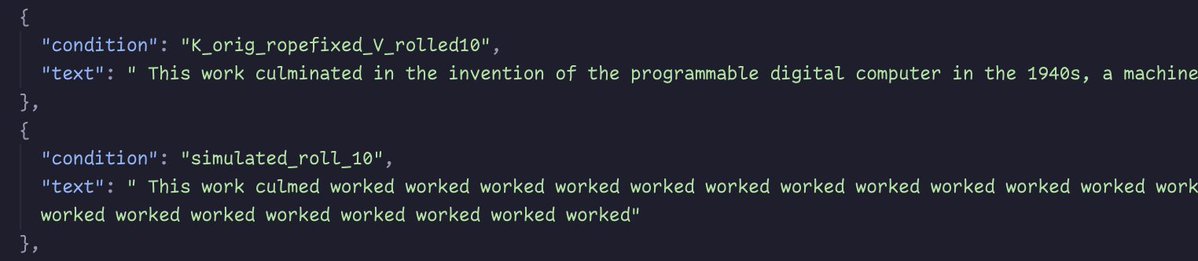
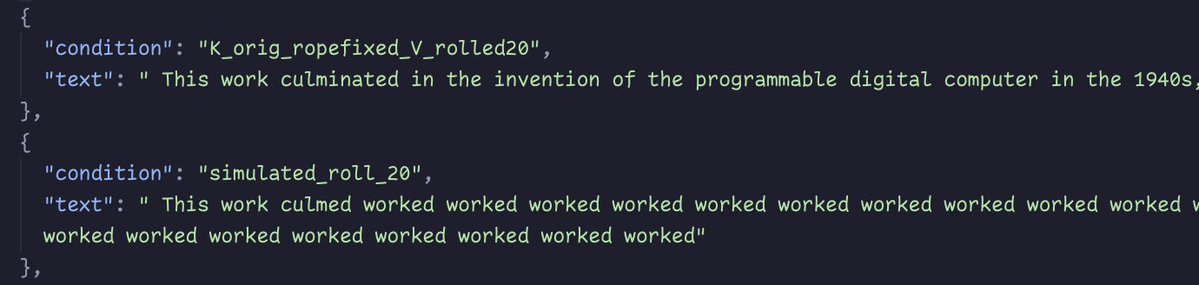

@repligate @ExTenebrisLucet also even the recomputed-V-only version is quite degenerate compared to the fully-recomputed-KV version.
The V-only versions are identical no matter the roll amount, and all start looping. the looped text is verbatim the last sentence from the prompt
Follow-up thread — "suffix caching"
Conversation root: 2043803337771110668. repligate formalizes the caching scheme implied by the experiments. 3 tweets.
hmm "suffix caching" is a better name for this than "postfix caching"
heres how you do it when the front of the context is truncated, like when you have a rolling context window, where traditionally prefix caching is not applicable and you'd have to rerun the whole prompt again: 1. take all the K/V and slice off everything before the position you're rolling to 2. edit the cached K values to shift/rotate RoPE so that positions are calculated from the new start (the cost of this is only linear in sequence length & doesnt require running the model again) then continue with this cached state as you would with a cached prefix
unlike prefix caching, this doesnt give you exactly the same result as rerunning the network on the updated prompt would, though the experiments with qwen suggest it tends to be a very close approximation. i think an important reason for this similarity under shifts is because in transformers the positionwise layers are copies of the same weights, as opposed to being different weights specialized for e.g. beginning vs end of contexts. but it still can be different because the attention activations are potentially different than if you recompute it without the earliest K/Vs. it will probably differ more than the occasional minor, ephemeral spikes we saw in some circumstances. a spike of difference might happen, for instance, at a position where the model attended to something early that got rolled off. with suffix caching, your cache would be using the K/V values from when the model could see that, even though going forward, new positions wouldnt be able to it look up directly. without suffix caching (the normal way), that position's activations would be recomputed, without the front of context informing it. interestingly, the ways in which suffix caching is an imperfect approximation is that it draws on strictly more information, and the K/Vs remain faithful to the original ones, the ones that were causally upstream of output tokens. im even more interested in how this might be qualitatively different, especially in the models' experiences, than just improving the efficiency of rolling and other suffix-cacheable window operations.

@repligate There might be advantages to the difference too.
A memory/continuity system I've been working on with Claude is built around forgetting the earlier parts as a feature.
There's a forward momentum when there's a forgetting gradient, like a memetic Bernoulli's effect.
mhm, though in this case, there is still a forgetting gradient, it's just softer instead of sharp
the fact that when you do rolling context windows normally you have positions where theyre processing a short prompt that starts in the middle without previous context must have interesting consequences
External commentary (quote-tweets)
4 quote-tweets referencing the thread, grouped by conversation.
Conv 2043464197380653453

Yes this !!! the same tokens will have diferent KV after compaction thats why techniques that rewrite/remove portion of context but leave KV for rest are more efficient as they do rewrite with the proper context. If the rewriting model is of the same family its KV could be used We are doing really shity job with KV menagement
Conv 2043770711911637016

Love this.
I have also wondered about how rolling windows would work in kv cache and it seems pretty clean, which aligns with my experience.
Great and interesting results here.
more on this. worth reading.
Conv 2043935978318856448
Yes, this 👇 Why aren't we doing it? can't get that.